

Organizations have years of valuable information buried inside lengthy reports, scattered across meeting notes, tucked away in policy documents and spread through countless emails.
Everyone knows the answers are in there somewhere, but finding them is like searching for a specific star in a cloudy night sky.
Now imagine if, instead of going through all that unstructured text manually, you could press a button and see it transformed into a neatly organized network of connected ideas. Suddenly, patterns emerge, dependencies become clear and questions that once took hours to answer are resolved in seconds.
That’s exactly what we achieve by using an ontology, a structured definition of the domain we’re working on. For example, in a content management setting, our ontology might define concepts like ContentType, Field and Workflow, along with relationships such as hasField or usesWorkflow. With these definitions in place, free-form text can be systematically converted into structured, queryable data.
Unstructured to structured content mapping
In Contentstack, content types such as Blog Post, Product Page or FAQ are made up of fields like title, body, category and image. However, the definitions for these content types are often scattered across multiple documentation pages. Without a clear structure, it becomes difficult to trace relationships, surface answers to specific questions or maintain consistency, leading to confusion and unnecessary time spent searching.
A knowledge graph changes that.
It brings together all the information into a single, connected view linking ContentType nodes with their Field nodes, and further connecting them to related Workflow and Taxonomy nodes.
This means you can run queries like “Which content types use a review workflow and include a ‘category’ field?” and get precise answers instantly.
From chaos to clarity: The 4-step process
Transforming unstructured text into a knowledge graph may sound complex, but it becomes far more approachable when broken down into clear, practical steps. Instead of thinking of it as one big leap from raw text to structured graph, follow a systematic pipeline as follows:
- Chunk the unstructured text so each piece is manageable and contextually intact.
- Extract entities using GLiNER (Generalist Lightweight Model for Named Entity Recognition), mapping them to our ontology.
- Build triples from the identified entities and relationships.
- Load triples into a graph database for querying and analysis.
Chunking text with a recursive character text splitter
The industry standard for processing is to break down long documents into smaller, manageable chunks for efficient processing. However, many basic splitting methods risk cutting sentences mid-way, leading to loss of context and meaning.
The Recursive Character Text Splitter eliminates this problem. It intelligently breaks text at natural boundaries like periods, line breaks or commas, ensuring terms aren't split between the sentences. It keeps each chunk with an almost equal number of words while preserving meaningful context. It stores each piece as its record, which makes processing clear and fast.

Extracting entities with GLiNER
Once the text is fully chunked, send each of the chunks to GLiNER for extracting the entities present in them. Use GLiNER, a zero-shot NER technique, because it allows us to extract entities directly based on a predefined ontology without the need for domain-specific training, with good accuracy, since no training with the new data is needed for the extraction of entities.
For example, it might identify:
- ContentType: Blog Post
- Field: title
- Workflow: Review Workflow

Building triples from Entities and Relations
Pick subject, relation and object from each of the chunks and create triples.
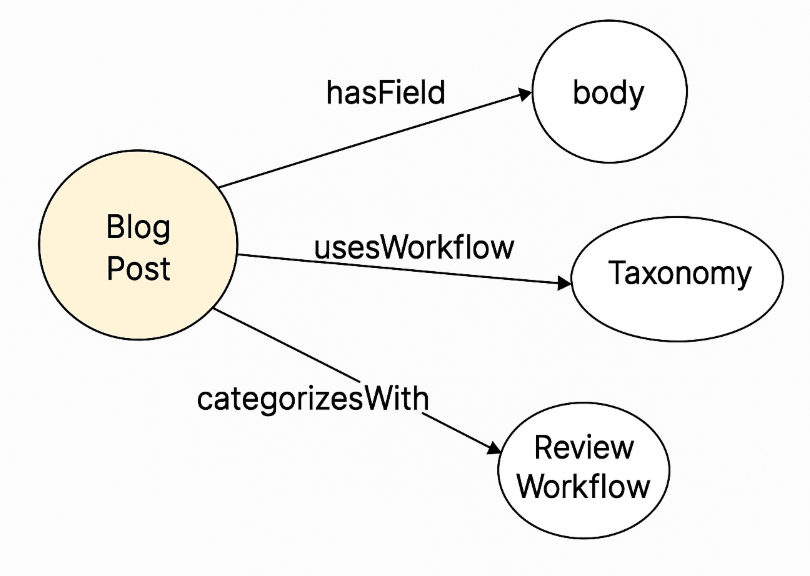
- (ContentType: Blog Post, hasField, title)
- (ContentType: Blog Post, hasField, body)
- (ContentType: Blog Post, usesWorkflow, Review workflow)
- (ContentType: Blog Post, categorizesWith, Taxonomy)
Map each of the triples accordingly from each of the chunks and save them in a table or CSV file.
Creating the knowledge graph
Triples alone are like individual puzzle pieces; you can see what each one represents, but not how the whole picture fits together. The real power lies in connecting these triples into a knowledge graph.
Here, Subjects and Objects from triples become Nodes, while relations form the Edges that link them. Once loaded into a graph database, nodes can be indexed by class and edges by type.
Complex queries such as “List content types that use review workflow but do not include a 'category' field” extract the relevant triples and produce the information without any manual hunts.
Tips for newcomers
- Install a Recursive Character splitter library or script.
- Map GLiNER labels to your ontology classes.
- Write a small loop to call GLiNER on each piece.
- Format triples in code or a spreadsheet.
- Load them into a graph system such as Neo4j or an RDF store.
By turning messy, unstructured text into a structured, searchable knowledge graph, the ability to explore information in ways that were previously too slow or impossible, whether it’s managing content types in Contentstack or mapping entirely different domains, is unlocked!
///////
Vidya Charan, ML Engineer at Contentstack, is passionate about AI and ML, with a focus on NLP, knowledge graphs and advancing LLM capabilities. Follow him on LinkedIn.


