

.svg?format=pjpg&auto=webp)
.svg?format=pjpg&auto=webp)
.png?format=pjpg&auto=webp)






.png?format=pjpg&auto=webp)
What You Need to Know About E2E Testing with Playwright



Contentstack recently launched Marketplace, a one-stop destination that allows users to find, create and publish apps, connect with third-party apps and more. It aims to amplify the customer experience by enabling them to streamline operations. Marketplace now has a few Contentstack-developed apps and we will introduce more in the future.
Initially, we tried to test these apps manually but found this too time-consuming and not scalable. The alternative was to use an end-to-end (E2E) testing tool (Playwright in our case), which helped us streamline and accelerate the process of publishing the apps.
Playwright is a testing and automation framework that enables E2E testing for web apps. We chose Playwright because of its classic, reliable and fast approach. Besides, its key features such as one-time login, web-first approach, codegen and auto-wait make Playwright suitable for the task at hand.
This article will walk you through the processes we used and the learnings we gathered.
Our Testing Processes
In this section, we detail the processes we followed to test the Marketplace apps using Playwright.
Set-up and Tear-down of Test Data
Playwright permits setting up (prerequisites) and tearing down (post-processing) of test data on the go, which helped us accelerate our testing.
There are additional options available for this:
global set-up
global tear-down
beforeAll & afterAll hooks
beforEach & afterEach hooks
Ideally, a test establishes prerequisites automatically, thereby saving time. Playwright helped us do that easily. Once the test was concluded, we deleted the app, content type, entry or the other data we initially set up.
Playwright helped us achieve the following on the go:
Auto-create app in the dev center
Auto-create content type and entry
Test Directory Structure
We added all the test-related files and data to the test's repository. The following example explains the process:
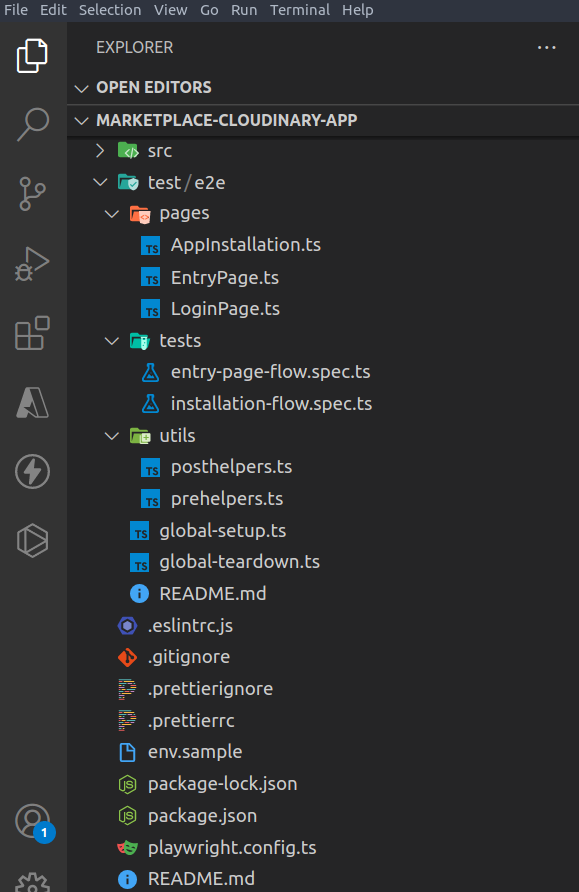
For the illustration app (see image below), we added the E2E test inside the 'test/e2e' folder.
Next, we included the 'page-objects/pages' (diverse classes) for multiple web pages and tests. The Page Object Model is a popular pattern that allows abstractions on web pages, simplifying the interactions among various tests.
We then placed the different tests (spec.js) under the test folders and the utility operations under /utils
All the dependencies of E2E tests were put in the same .json package but under dev dependencies.
We attached .env(env. sample) with correct comments to add the environment variables correctly.
After that, we added support for basic auth on staging/dev.
In the next stage, we added the Readme.md details about the project.
We used the global-setup for login management to avoid multiple logins.
Next, we used the global-tear-down option to break the test data produced during the global-setup stage.
Finally, we used beforeAll/afterAll hooks to set-up/breakdown test data for discrete tests.
How to Use Playwright Config Options & Test Hooks
Global-setup & Global tear-down:
Both global-setup and global tear-down can be configured in the Playwright config file.
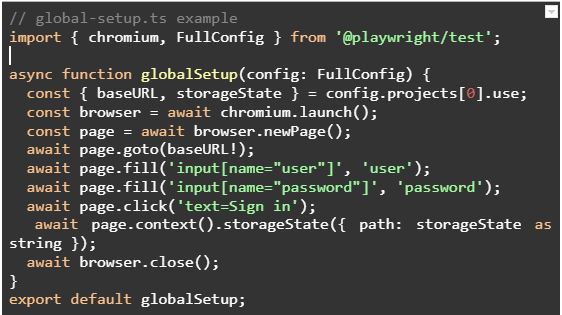
- Use global-setup to avoid multiple logins (or any other task later required during the test execution) before the tests start:
Global set-up easily evades repetitive steps like basic auth login and organization selection.
That way, when the tests are conducted, the basic requirements are already in place.
Below is the example of a sample code snippet for a global set-up:
- Use global-tear-down to break down any test data created during the global-setup file.
The test data generated using global-setup can be eliminated in global-teardown.
While global-setup/global-teardown are the config option/s for an entire test suite, before/after tests hooks are for the individual tests.
Test Hooks Available in Playwright
Playwright hooks improve the efficiency of testing solutions. Here is a list of test hooks available in Playwright:
test.beforeAll & test.afterAll
The test.beforeAll hook sets test data shared between test execution like entries, creating content types and establishing a new stack. The test.afterAll hook is used to break or tear the test data. This option helps eliminate any trace of data created for test purposes.
test.beforeEach&test.afterEach
This hook is leveraged to set up and break down test data for individual tests. However, the individual text execution and the concurring data might vary. Users can set up the data according to their needs.
Tips & Tricks for Using Playwright
While using Playwright, we learned a few valuable lessons and tips that could be useful to you:
Using the codegen feature to create tests by recording your actions is a time-saving approach.
You can configure Retires in the playwright config file. It helps in case of a test failure. You can re-run the test to come up with relevant results.
The Trace Viewer allows you to investigate a test failure. This feature includes test execution screencast, action explorer, test source, live DOM snapshots and more.
Use the timeout feature for execution and assertion during testing.
By setting up a logger on Playwright, you can visualize the test execution and breakpoints.
Using the test data attributes during a feature development navigates the test through multiple elements, allowing you to identify any element on the DOM quickly.
Recommended Best Practices
While using Playwright for E2E testing of our marketplace apps, we identified a few best practices that might come in handy for other use cases.
Parallelism:
Test files run by default on Playwright, allowing multiple worker processes to run simultaneously.
Tests can be conducted in a single file using the same worker process.
It's possible to disable the test/file execution and run it parallelly to reduce workers in the config file.
The execution time increases with the number of tests; parallelly running tests are independent.
Isolation:
Each browser context is a separate incognito instance, and it's advisable to run each test in individual browsers to avoid any clash.
In isolation, each browser can emulate multi-page scenarios.
It's possible to set up multiple project requirements in playwright config as per the test environment similar to baseURL, devices and browserName.
Speed of Execution:
Parallel test execution, assigning worker processes and isolation expedite the running of test results.
Elements like test data, global tear-down and set-up affect the execution speed regardless of the number of worker processes.
Double Quotes Usage:
Use double quotes if you come across multiple elements on the exact partial string.
Help establish case sensitivity. For instance, awaitpage.locator('text=Checkout') can return both elements if it finds a "Checkout" button and another "Check out this new shoe."
The double usage quotes can also help return the button on its own, like await page.locator('text="Checkout"'). For details, check out the Playwright text selectors.
Prioritizing User-facing Attributes:
It's advisable to use user-facing elements like text context, accessibility tiles and labels whenever possible. Avoid using "id" or "class" to identify elements. For example, use await page.locator('text=Login') instead of await page.locator('#login-button') is recommended.
A real user will not find the id but the button by the text content.
Use Locators Instead of Selectors:
Locators will reduce flakiness or breakage when your web page changes. You may not notice breakages when using standard selectors.
Example:se await page.locator('text=Login').click() instead of await page.click('text=Login').
Playwright makes it easy to choose selectors, ensuring proper and non-flaky testing.
Wrapping Up
In a world dominated by Continuous Integration and Delivery, E2E testing is the need of the hour. Though it's a tedious task, following the practices above will save you time and improve your product.
About Contentstack
The Contentstack team comprises highly skilled professionals specializing in product marketing, customer acquisition and retention, and digital marketing strategy. With extensive experience holding senior positions at renowned technology companies across Fortune 500, mid-size, and start-up sectors, our team offers impactful solutions based on diverse backgrounds and extensive industry knowledge.
Contentstack is on a mission to deliver the world’s best digital experiences through a fusion of cutting-edge content management, customer data, personalization, and AI technology. Iconic brands, such as AirFrance KLM, ASICS, Burberry, Mattel, Mitsubishi, and Walmart, depend on the platform to rise above the noise in today's crowded digital markets and gain their competitive edge.
In January 2025, Contentstack proudly secured its first-ever position as a Visionary in the 2025 Gartner® Magic Quadrant™ for Digital Experience Platforms (DXP). Further solidifying its prominent standing, Contentstack was recognized as a Leader in the Forrester Research, Inc. March 2025 report, “The Forrester Wave™: Content Management Systems (CMS), Q1 2025.” Contentstack was the only pure headless provider named as a Leader in the report, which evaluated 13 top CMS providers on 19 criteria for current offering and strategy.
Follow Contentstack on LinkedIn.

Recommended posts



