

.svg?format=pjpg&auto=webp)
.svg?format=pjpg&auto=webp)
.png?format=pjpg&auto=webp)






.png?format=pjpg&auto=webp)
Micro-Frontend Approach for Enterprise-Grade React Applications


Microservices have revolutionized the way we develop modern apps. And that’s primarily because of the huge advantage they bring along: Innovate faster by breaking down large products or projects into smaller, manageable pieces that you can move, update, or replace quickly. We have built our award-winning products based on this approach, and it has helped us scale incredibly fast.
That’s the story of our backend.
Our frontend, however, until some time ago, was still monolithic. We wanted to take a similar approach for our frontend to get the benefits of “microservices” there. This approach is called a “micro-frontend.”
In the last few months, we tried and tested a few methods, and finally, we successfully implemented a micro-frontend for our application. We learned quite a few crucial lessons in the process. This blog is about these lessons. It’s not a theoretical introduction to micro-frontend nor a definitive guide to implementing it. It’s more about our journey of building micro-fronted for our applications, some lessons we learned, and sample code to help you build yours.
Why We Chose Micro-Frontend
A single, unified frontend works well until your app is catering to only a handful of customers. As you grow and start adding more capabilities, the inflexibility of a single, large frontend starts to throttle the pace of your delivery.
We have broken down our product into several sub-domains, with each one being developed and owned by separate teams. When the different codebases from all these teams came together into a single application, there were natural consequences:
- All the teams had to sync often on deployment and testing
- Releases needed to be coordinated across the different teams and their schedules
- Merge conflicts occurred frequently
It was not an efficient approach and certainly not scalable. Dividing the frontend into smaller apps was the need of the hour.
The Approach
There are several ways to build micro-frontends. We did some initial research and found the following two ways to be more suitable for our requirements:
- Iframes
- Approach as defined in https://micro-frontends.org/
We tried the “iframes” approach initially. It was, however, not a very effective approach, as it has issues related to security, usability, and SEO. However, it helped us bootstrap a repository and get the micro-frontend on the screen to start development.
The second approach, as suggested by micro-frontends.org, was interesting because it leverages custom DOM elements. While the approach is well thought out, we realized that it could be overkill for us since we don’t use multiple frameworks — we use ReactJS across projects — and we don’t have many use cases for out-of-the-frame rendered components.
Later, we came across the blog: 5 Steps to Turn a Random React Application Into a Micro Front-End. It suggests a few methods to help implement a micro-frontend the way we wanted, and they eventually became the base for our implementation. Let’s look at the methods in detail.
The Implementation
As defined in the blog, the basic implementation includes using a dynamic script tag to load the micro-frontend JavaScript on the page. Once loaded, the container calls a method on the window object. The micro-frontend provides this method to start the rendering process. The micro-frontend renders to a div as exposed by the container. Eventually, you get a setup that looks like the illustration below.
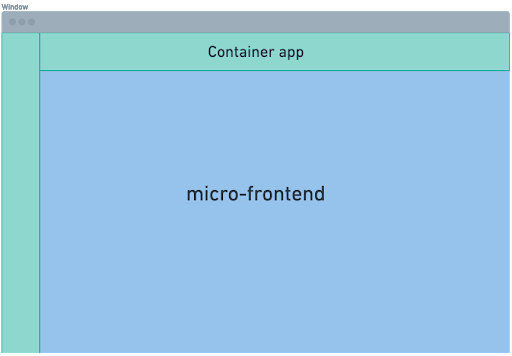
The container app renders sections in green, and the section in blue is the micro-frontend.
Challenges with rendering outside the micro-frontend — and the solution
While the initial success using the above approach was quite encouraging, it was short-lived. We faced a significant challenge, and we quickly realized that our implementation needed to be slightly different:
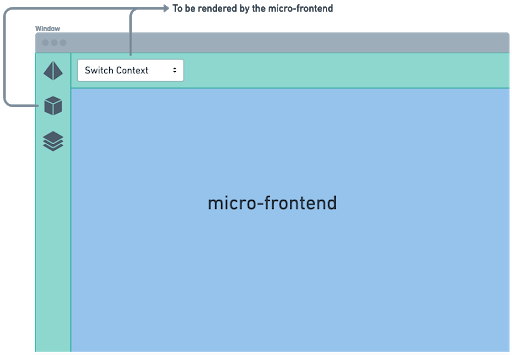
As you can see in the illustration above, the micro-frontend also needed to render a few components outside its DOM hierarchy. The left navigation bar and the top header need to render certain buttons, icons, and other components sourced from the micro-frontend.
After some basic troubleshooting, we realized that we could use the React Portals API to solve this. This API allows you to render components outside the DOM tree where the micro-frontend is rendered. Using some well-known div IDs, we were able to expose an API where the micro-frontend can control these sections in the UI.
Another challenge was to have a seamless routing experience when the micro-frontend wanted to change routes. Managing this became a little easier since we are creating a single-page application (SPA) with HTML 5 pushState API. When initializing the micro-frontend, we could pass the history object, which the micro-frontend can then use. Also, we used relative routes, so it worked without a hitch.
Challenges With Rendering Outside the Micro-Frontend — and the Solution
One unfortunate side effect to having independent micro-frontends is the relative size of each micro-frontend JavaScript bundle. Nowadays, loading an average ReactJS app and all the standard libraries consumes several megabytes of bandwidth. By implementing micro-frontends, we were going to multiply this with the number of micro-frontends in use.
Some of the libraries that we use (such as React, Redux, Redux-Saga) are common among all the micro-frontends we have built. So, it did not make sense to download these common libraries for each micro-frontend. Instead, a better approach would be to bundle them together so you could download them only once. We achieved this using dll-plugin, a library for Webpack. It allows us to bundle the common libraries into a “DLL” (Dynamically-Linked-Library) that you can dynamically load within a webpack project. By using the DLL plugin, we achieved a significant 60% reduction in our bundle size.
Summary
Our application’s new user interface and some of our new incubation projects now have micro-frontends implemented, based on the approach given above. And all these apps have been working smoothly. We can roll out more changes quickly with less dependency on other teams, so deployment and scaling become more manageable.
If you want the details of this approach, check out our micro-frontend example (with code) on GitHub.
About Contentstack
The Contentstack team comprises highly skilled professionals specializing in product marketing, customer acquisition and retention, and digital marketing strategy. With extensive experience holding senior positions at renowned technology companies across Fortune 500, mid-size, and start-up sectors, our team offers impactful solutions based on diverse backgrounds and extensive industry knowledge.
Contentstack is on a mission to deliver the world’s best digital experiences through a fusion of cutting-edge content management, customer data, personalization, and AI technology. Iconic brands, such as AirFrance KLM, ASICS, Burberry, Mattel, Mitsubishi, and Walmart, depend on the platform to rise above the noise in today's crowded digital markets and gain their competitive edge.
In January 2025, Contentstack proudly secured its first-ever position as a Visionary in the 2025 Gartner® Magic Quadrant™ for Digital Experience Platforms (DXP). Further solidifying its prominent standing, Contentstack was recognized as a Leader in the Forrester Research, Inc. March 2025 report, “The Forrester Wave™: Content Management Systems (CMS), Q1 2025.” Contentstack was the only pure headless provider named as a Leader in the report, which evaluated 13 top CMS providers on 19 criteria for current offering and strategy.
Follow Contentstack on LinkedIn.

Recommended posts



