
From legacy systems to microservices: Transforming auth architecture

Highlights
You'll learn how to:
- Leverage modern design patterns: Use contemporary architectural patterns for developing efficient authentication and authorization solutions.
- Deploy access tokens efficiently: Transfer access tokens from the periphery to individual microservices, and you can ensure effective authentication in a microservices environment.
- Acknowledge authorization challenges: Developers must understand that while authentication issues are addressed by mature standards like OAuth2 and OIDC, authorization presents unique challenges.
- Customize access decision managers: Enhance your authorization architecture by personalizing your AccessDecisionManager or AccessDecisionVoter.
Organizations can successfully transform their auth architecture by understanding and implementing these key points. Keep reading to learn more!
Contentstack receives billions of API requests daily, and every request must be validated to be a valid Contentstack identity. It is a common industry practice to achieve this using some sort of “identity token" for every request. Imagine having multiple types of identity tokens, such as session tokens, OAuth tokens, delivery tokens, management tokens, etc.
The problem of securing billions of API requests daily can be challenging. We decided to address this by spinning up a new team that handles the complex problems of user authentication and authorization in a token-agnostic platform.
Our transition journey
Contentstack started as an API-first headless CMS platform that allowed content managers to create and manage content while simultaneously and independently enabling developers to use Contentstack's delivery API to pull that content and render it to create websites and applications. This means that Contentstack’s traffic increases proportionately to the traffic received by our customers' websites and applications.
With increased traffic and usage, we catered to various new use cases by developing new features. These features were powered by a set of microservices, each catering to a particular feature domain and needing support for processing multiple identity tokens that had roles and permissions associated with them. The whole system had turned out to be quite complex, and performing auth had become a great challenge. This prompted us to redesign our auth architecture, which addressed the issues of being a token-agnostic and low-latency platform.
Read on to learn more about this journey and how we have been able to:
- Transition from a monolith to a low latency microservices-based auth (authentication plus authorization) and rate-limiting architecture.
- Set up centralized authentication for multiple (any domain) microservices that are part of the same Kubernetes cluster.
- Set up decentralized and self-serviced, policy-based authorization for internal services and teams.
Monolithic auth architecture
Monolithic architectures can be difficult to maintain, scale and deploy. In a monolithic architecture, user authentication and authorization are typically tightly coupled with the application code, making it difficult to implement and maintain robust security measures. Monolithic architectures often rely on a single authentication and authorization mechanism for the entire application, which can limit the flexibility of the system to accommodate different types of users or access levels.
{{nativeAd:3}}
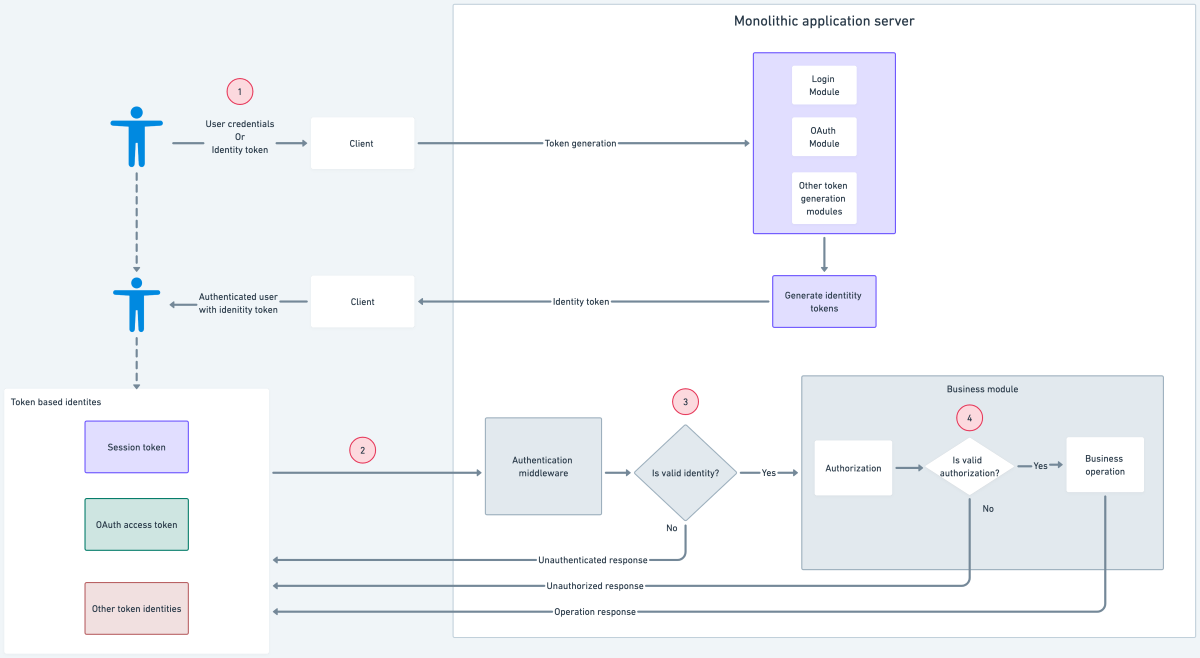
In monolithic architectures, the steps involved in auth are the following:
- Users use their credentials at the client to generate a session token or use an existing identity token to generate other identity tokens.
- Users then use the generated identity token to perform a business operation by making a request to the application server.
- Once a request is received at the application server, the authentication middleware authenticates the token and forwards the request to the business module.
- The business module performs the business operation based on the authorization rules applied to the user identity.
Problems with monolithic auth architecture:
- Authentication and authorization logic is mixed with the business logic.
- Changing the way an identity performs an operation on a resource involves a change in the associated auth-related logic.
- Each domain individually implements the authorization logic, causing a difference in implementation.
- Since authorization logic is deeply nested in business logic, we lack visibility into authorization rules applied to a resource.
- Shipping of new authorization logic requires a fresh deployment of the application image.
- New microservices require knowledge of various identity tokens and resource authorization rules to be applied.
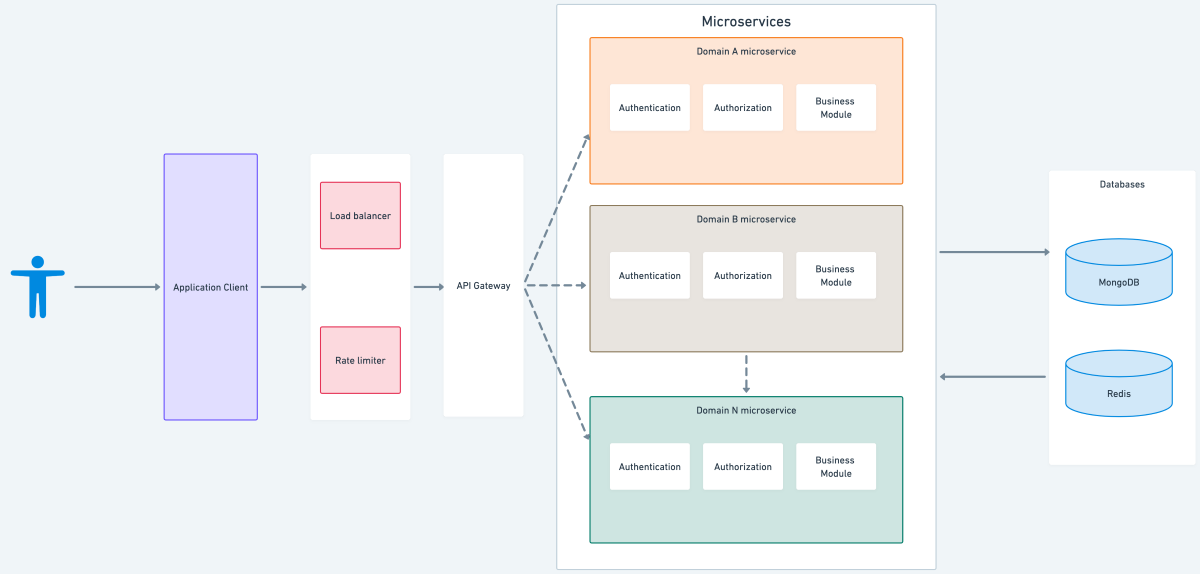
Microservices auth architecture
Microservices offer a more flexible, modular approach that allows for easier maintenance, scalability and deployment. With microservices, each service can be developed, deployed and scaled independently, allowing for faster time-to-market, improved fault tolerance, and better alignment with modern development practices. Additionally, microservices offer more efficient use of resources and better support for diverse technology stacks.
Authentication
Why centralized authentication?
Centralized authentication is a security model in which a central authority manages authentication, such as a server or service, rather than it being distributed across multiple systems or applications. There are several reasons why centralized authentication is commonly used and considered advantageous, including increased security, simplified management, improved user experience and lower costs.
While there are some drawbacks to centralized authentication, such as the increased risk of a single point of failure and increased complexity in managing the central authority, the benefits often outweigh the risks.
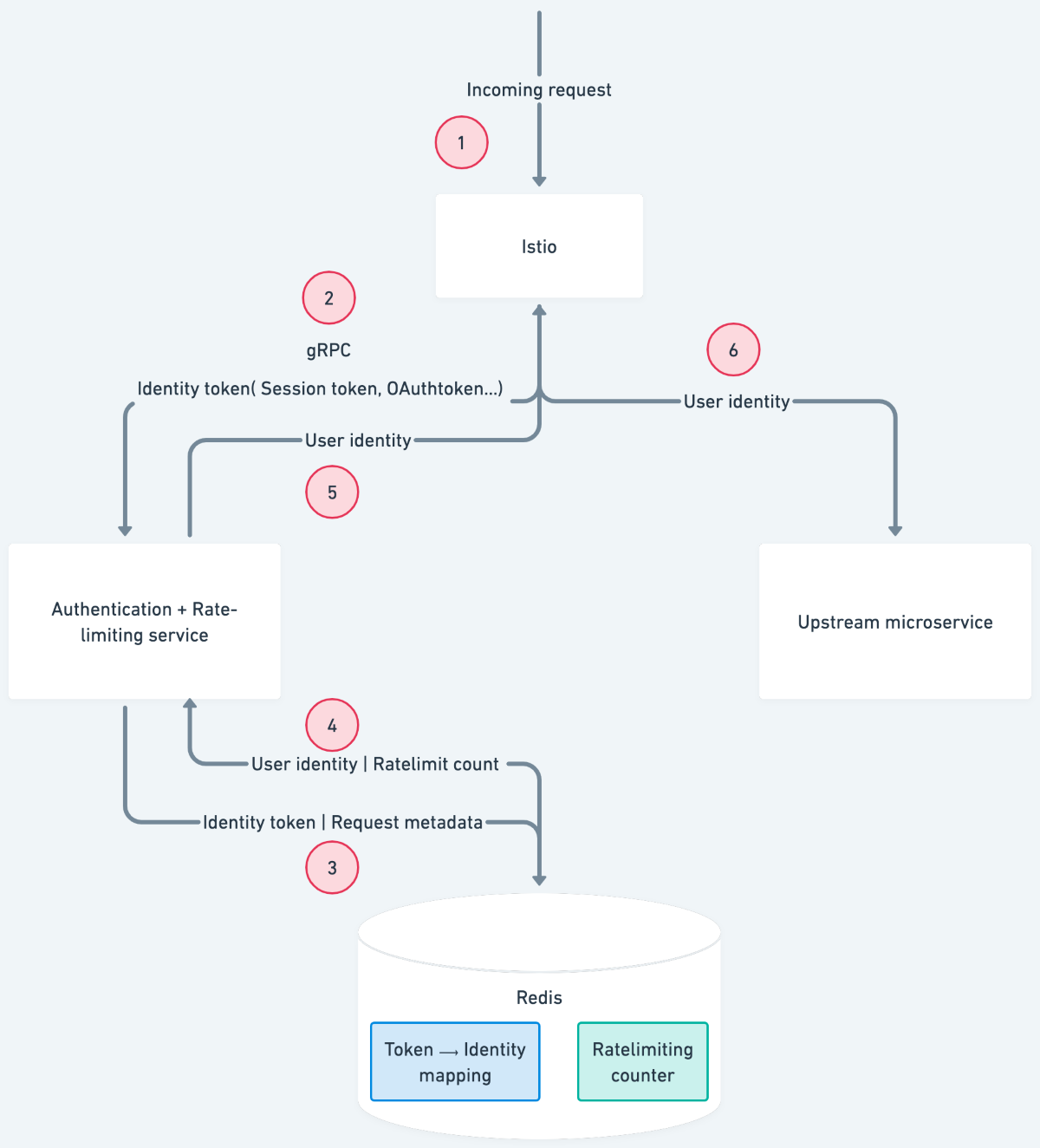
The steps involved in the centralized authentication process are the following:
- Any incoming request to the Kubernetes cluster first lands at the Istio ingress gateway.
- The request containing the identity token is proxied to a central authentication gRPC service with the help of envoyproxy's external authorization filter.
- The central authentication service queries Redis with the identity token and metadata associated with the request.
- Redis responds with the identity associated with the token and the current rate-limit count based on the request metadata.
- The central authentication service responds to Istio with either of the following:
- Authenticated response with user context attached to the request in the form of request headers
- Unauthenticated response
- Ratelimit exceeded response
- An authenticated request containing the user context is then forwarded to the upstream service.
Advantages over the monolithic architecture:
- Easier to onboard newer microservices to central authentication service by using label based istio-injection.
- All requests are authenticated and rate-limited at the edge of the service mesh, ensuring that each request entering the cluster is always rate-limited and authenticated.
- The request forwarded to the upstream microservice has user identity context attached to it in the request headers, which can be further used for applying authorization rules.
- Keeping centralized authentication eliminates the problem of multiple mutations performed by the upstream microservices on the identity of the token.
Authorization
Centralized authorization
We tried a model where along with authentication and rate limiting, we also added authorization as a responsibility of the central authentication and rate limiting service. The service would first identify the incoming request’s identity from the token and apply rate limiting based on the request metadata. Once the user identity is known, authorization rules could be applied to the user’s identity, thereby performing the entire Auth at the edge of the service mesh.
Problems with this model are the following:
- This model could only perform basic authorization at the edge based on the request metadata provided, such as validating organizations, stacks, etc. However, it could not perform fine-grained authorization, such as finding out which content types the logged-in user had access to.
- For RBAC, each domain has its roles and permissions associated with it; performing authorization for such requests requires knowledge of the upstream domain and leads to the addition of domain-specific logic in the centrally managed domain-agnostic platform.
- With newer domain microservice additions, this again would lead to the problem of lacking visibility into authorization rules applied to a resource.
Distributed authorization with central authorization service
We then tried implementing a model where we distributed authorization to the upstream microservices where each upstream microservice makes a call to a central authorization service. The authorization service has access to all the roles and permissions of different domains and was able to give appropriate authorization results. Authorization could now be performed from the upstream service’s business module by making a network request using Kubernetes cluster networking to avoid making a call over the internet.
Problems with this model are the following:
- The central authorization service becomes a single point of failure.
- Any change in the API contract defined by the central authorization service requires all the upstream services to abide by it and makes shipping these changes independently a complex task.
- Performing authorization adds a network hop, thereby increasing the latency.
Distributed authorization with the sidecar pattern
Learning from the previously discussed disadvantages, we wanted to build a model that had authorization distributed, low latency and made shipping authorization logic an independent activity.
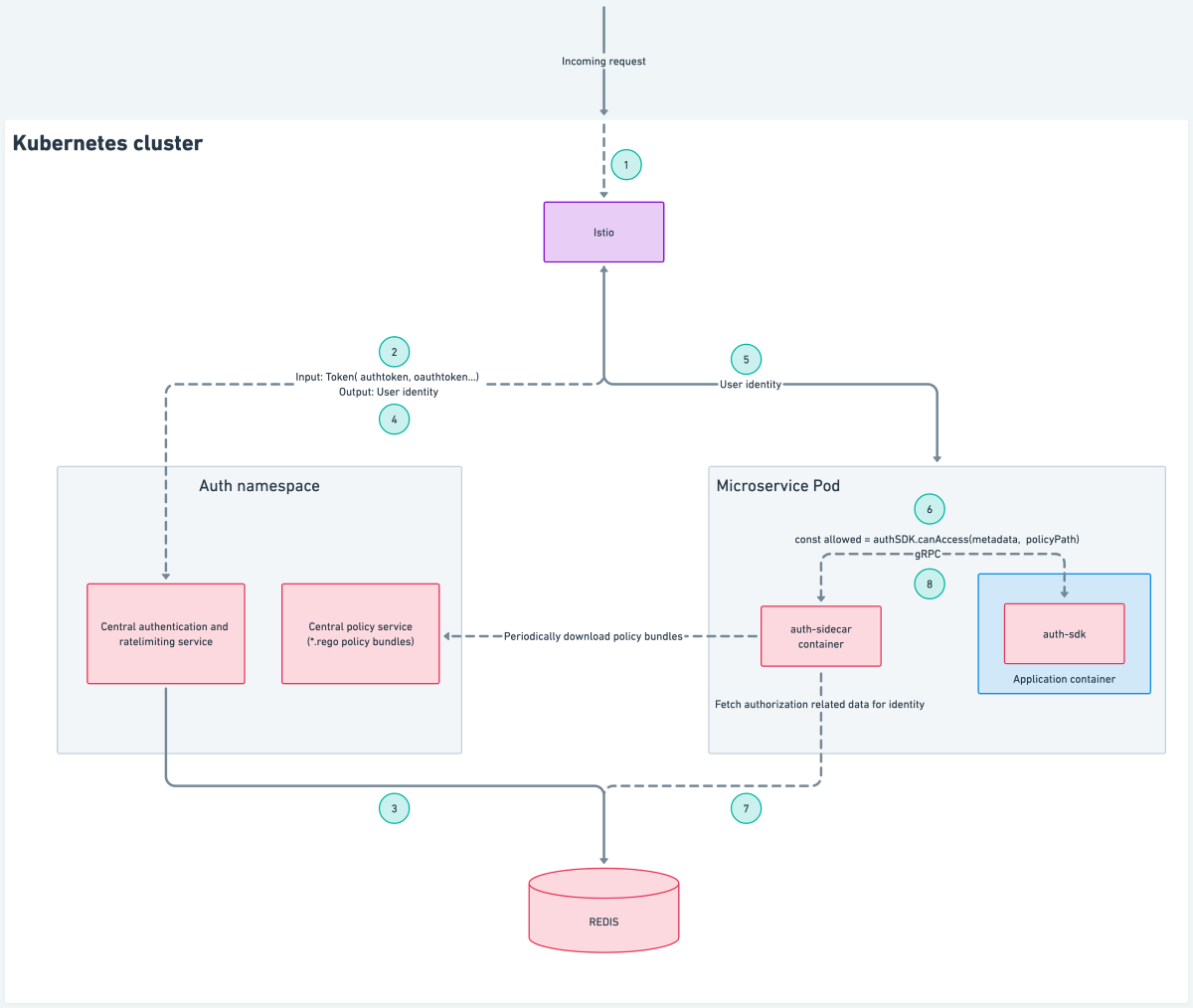
Architecture
The architecture involves the following components:
- Auth sidecar
- Central policy service
- Auth SDK
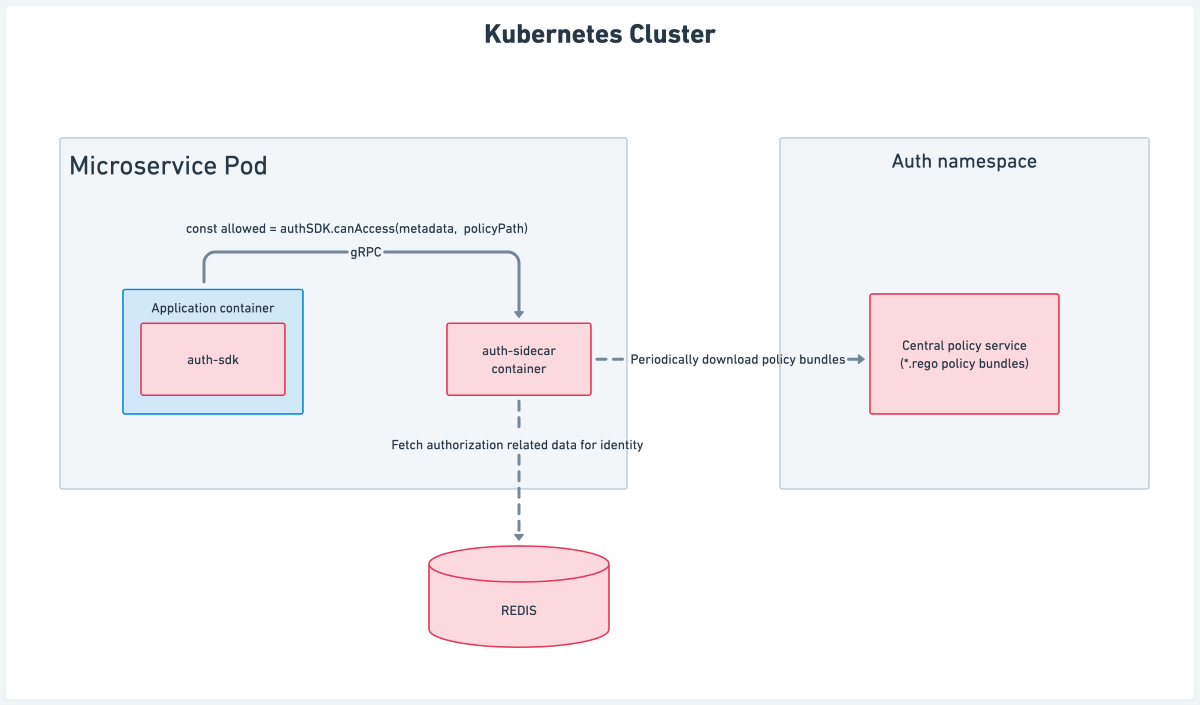
Auth sidecar
The auth sidecar is a gRPC service that gets injected along with the microservice’s application container in the same Kubernetes pod. Let’s understand how this architecture helped us tackle the previously mentioned problems.
Single point of failure: The auth sidecar service runs with the application container in the same pod, and any case of failure is only limited to the current pod. Restarting the pod gives us a fresh set of application and auth sidecar containers.
Independent delivery: Since the auth sidecar service container is shipped along with the application container, the application service can decide which version of the sidecar image to use, thereby making the delivery of newer versions of the authorization sidecar independent.
Low latency: There is no network hop involved in making a gRPC call to the auth sidecar running in the same pod. This helps the application to get the authorization result with very low latency (in a few milliseconds).
Updating authorization logic: The auth sidecar periodically downloads fresh policy bundles; any time there is a change in policy bundle coming from the central policy service, the auth sidecar updates its local policy cache with the new bundle.This way, updating authorization logic does not involve a fresh deployment/restart of the application container.
Components involved in auth sidecar
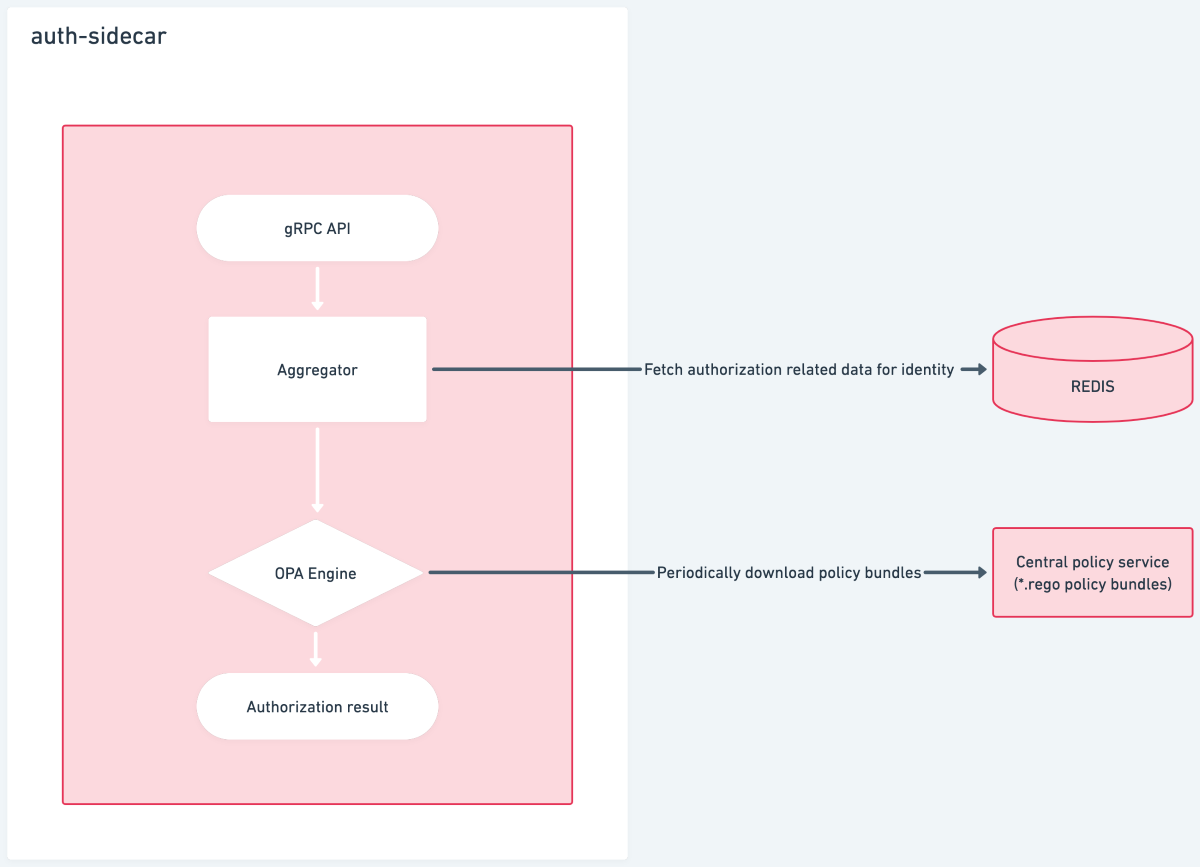
Aggregator: The responsibility of the aggregator is to fetch authorization-related data for the current identity based on the metadata provided by the application service in the gRPC call. It then aggregates it to be evaluated against the authorization policy.
OPA Engine: We use OPA (Open Policy Agent) to periodically download fresh policies and evaluate the policy path mentioned in the gRPC call against the aggregated data.
Central policy service
The central policy service is a repository of policy bundles (*.rego files) which are independently managed by the domain microservices. The maintainers of the domain microservices create these policies for various resources that need authorization. Since these policies only involve rules, it greatly increases the visibility of authorization rules being applied to a particular resource.
Auth SDK
The auth-sdk is an internal library that we developed that helps the developers of upstream microservices to easily communicate with different auth components. It can do the following:
Extract user identity and other useful information attached in the request headers by the central authentication service
Discover various auth components and streamline communicating with them
Expose different helper methods to perform any auth-related activity on behalf of the application service
Redesigned (new) architecture:
Conclusion
Microservices-based architectures can help address some of these challenges of monolithic architecture by separating user authentication and authorization into individual services, which can be developed, deployed and maintained independently. This approach can provide greater flexibility, scalability and security for user authentication and authorization.
However, it's important to note that transitioning to a microservices-based architecture can also come with some challenges, such as increased complexity and a need for more advanced DevOps practices. Proper planning, implementation and ongoing maintenance are crucial to ensuring a successful transition.
Share on